

1. Running CESM in Four Steps - Introduction#
Tutorial at the 2024 paleoCAMP | June 18–July 1, 2024
Jiang Zhu
jiangzhu@ucar.edu
Climate & Global Dynamics Laboratory
NSF National Center for Atmospheric Research
Learning Objectives:
Know basic structure of CESM as a software including the workspaces
Know how to set up a simple experiment with CESM
Know how to customize details of the experiment using xmlchange and namelist
Time to learn: 30 minutes
NOTE: Hands-on exercise is in the next module. You don’t need to do anything yet.
1.1. CESM as a software#
~5 million lines of FORTRAN* source code and scripts
You need to build the source code to create and run the executable.
Download the released CESM from Github*
git clone -b release-cesm2.1.5 ESCOMP/CESM.git cesm2.1.5
cd cesm2.1.5
./manage_externals/checkout_externals
Read more about CESM here
*NOTE: Why FORTRAN?
*NOTE: for this tutorial, please use the code in my workspace: /glade/work/jiangzhu/paleocamp/cesm2.1.5
1.2. CESM Workspaces (assuming you run a company that builds new electric vehicles)#
CESM Code, “Headquarter”
contains your intellectual properties, e.g., research/designing of EVs
FORTRAN, Python, & XML (Extensible Markup Language) files
Inputdata Directory, “Supply Warehouse”
contains the raw materials, e.g., steel and batteries
netcdf data
Case Directory, “Production Control Room”
where you give instructions, e.g., to hire 100 workers and produce 5 EVs per day
Text, script, XML files
Build/Run Directory, “Factory”
where workers assemble the EVs
Library, executables, netcdf files, …
Archive Directory, “Storage”
where you store the assembled EVs
netcdf files, log files in text, …
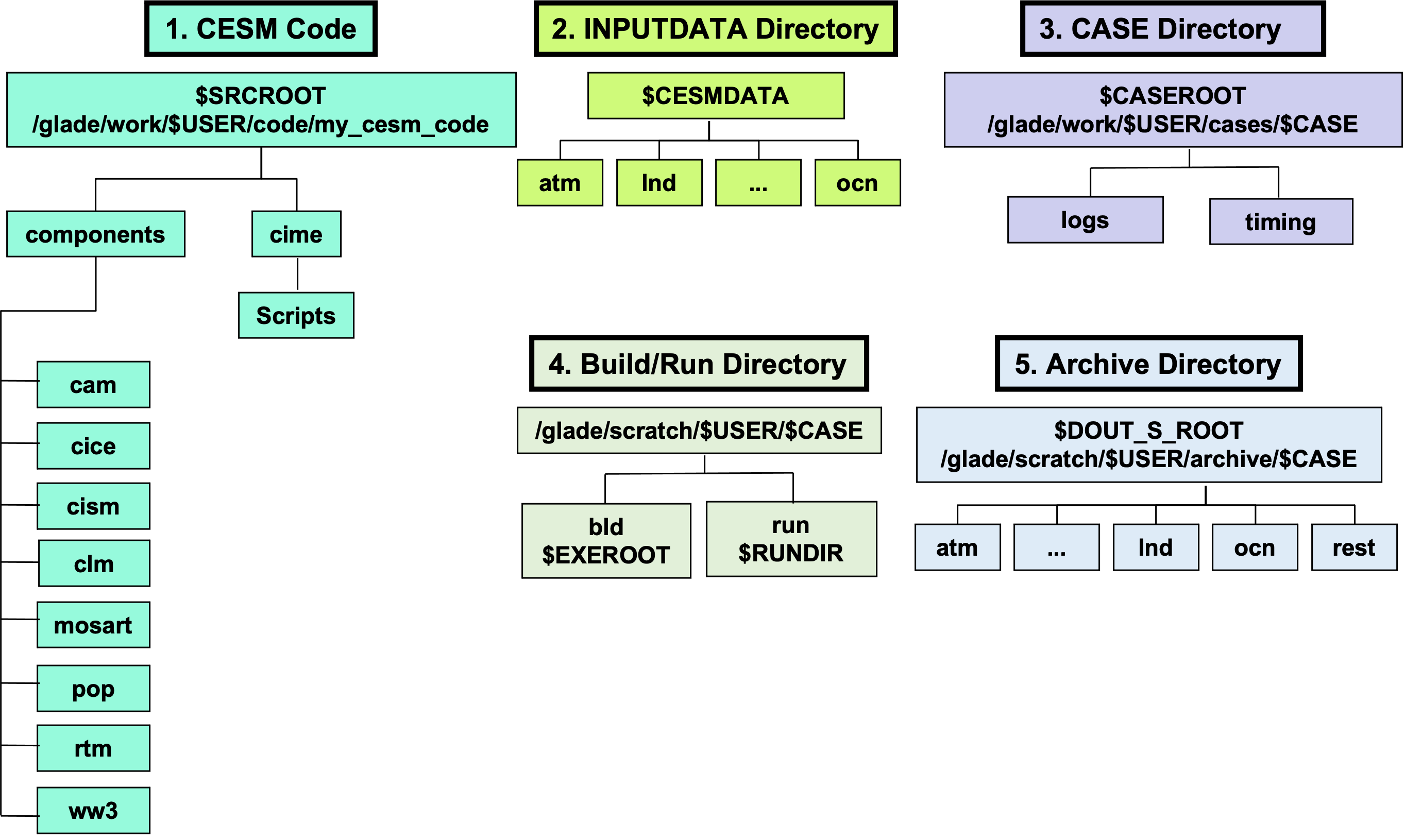
Figure: CESM2 Workspaces
1.3. Run a preindustrial control simulation in four steps#
Create a new case
case01in thehomedirectory (do this in the CESM Code Directory, the “Headquarter” and creates the “Production Control Room”)
cd /glade/work/jiangzhu/paleocamp/cesm2.1.5/cime/scripts/
./create_newcase --case ~/case01 --compset B1850 --res f19_g17 --project UAZN0035
Set up your case (do this in the Case directory, the “Production Control Room” and creates the “Factory”)
cd ~/case01
./case.setup
Build your case (do this in the Case directory, the “Production Control Room” and designs the manufacturing workflow)
./case.build
submit your run (do this in the Case directory, the “Production Control Room” and starts the manufacturing)
./case.submit
1.3.1. Further explanations on create_newcase#
The create_newcase command has three required inputs. It creates your “Production Control Room”.
--case: the name and directory path of your case (your Production Control Room)
Setting case to
~/case01will make a simulation calledcase01and it will be located in thehomedirectoryWe use
case01for simplicity, but here is the CESM case naming conventions
--compset: the CESM component set that you’d like to use.
CESM2 components can be combined in numerous ways to carry out various scientific experiments. A particular mix of components, along with component-specific configuration and/or namelist settings is called a component set or
compset.B1850means fully coupled preindustrial control including active atmosphere, land, ocean, sea ice, etc.F1850means atmosphere/land-only simulation with fixed sea-surface temperature and sea ice cover.Other supported compsets. Or
$CESMROOT/cime/scripts/query_config --compsets
--res: the resolution that you’d like to use.
f19_g17: ~2° atmosphere/land and ~1° ocean/sea ice.f09_g17: ~1° atmosphere/land and ~1° ocean/sea iceOther supported grid/resolution. Or
$CESMROOT/cime/scripts/query_config --compsets
1.3.2. Further explanations on case.setup#
case.setup creates the Build and Run Directory, which is your Factory.
case.setup also creates files like user_nl_cam, where users can customize component namelist settings.
case.setup should be invoked in the Case Directory (your Production Control Room).
1.3.3. Further explanations on case.build#
case.build check and builds component model namelists and libraries, and the final executable.
case.build may take 10 minutes!
Tips: if you first case.build fails somehow, run ./case.build --clean-all before trying to build the model again.
Note: it is recommended that you avoid building CESM on a shared login node via doing qcmd -- ./case.build (skip this if you use Terminal via JupyterHub)
1.3.4. Further explanations on case.submit#
case.submit submit the job to the HPC batch job scheduler.
case.submit also submit the case.st_archive script to archive the model output (move output from your Factory to Storage). This step is dependent on the successful completion of simulation.
1.4. Check job status#
qstat accesses the information in the Batch Job Scheduler to see the status of all jobs running on Derecho. To simplify the list down the -u option can be specified for a particular user.
qstat can be used in any directory on Derecho.
qstat -u $YOUR_USERNAME
Output:
Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time
--------------- -------- -------- ---------- ------ --- --- ------ ----- - -----
704942.chadmin* $USER regular run.b.day* 8284 16 576 -- 12:00 R 00:00
704945.chadmin* $USER regular st_archiv* -- 1 1 -- 00:20 H --
Note, there may be a slight delay from submitting CESM until the jobs appear in the queue. Once the jobs have completed, they will disappear from the qstat command.
1.5. Model output#
If the model run is successful, the CESM netcdf output history files are automatically moved to a short-term Archive Directory (Your Storage; /glade/derecho/scratch/YOUR_USERNAME/archive/YOUR_CASENAME).
Notes:
If a model run was unsuccessful the output remains in the Run Directory (your Factory) and the short-term archive is not created.
Both the Run Directory and the Archive Directory are in the NCAR HPC scratch space. This space is scrubbed, and files deleted after a number of days. Thus, it is a good idea to move your model output files from the short-term archive to a more permanent location as soon as you are able.
1.6. More controls: XML change#
Use the
./xmlchangecommand in the Case Directory, your “Production Control Room”
For example, change the simulation length of a single submission to 1 year (the default setting is 5 days):
STOP_OPTIONcontrols the units in which you are specifying the length of the simulationSTOP_Nis the length in those unitsxmlchangeofSTOP_OPTIONandSTOP_Nshould be done beofore./case.submitYou can check values of specific variables using:
You can find a listing of all the available XML variables along with their description in
env_run.xmlby running the following commands from your case directory
Note: Typically, supercomputers have a wallclock limit of 12 hours in real time, meaning that you can only run continuously for 12 hours. You can use
STOP_OPTIONandSTOP_Nto an appropriate length that can be completed wallclock limit.
1.7. More controls: namelist change#
Typically, it is used to control specific model parameters (CO2, cloud parameters, etc.)
Use text editor to edit the
user_nl_*files in the Case Directory, your “Production Control Room”For example, adding the following line into
user_nl_camwill change the CO2 concentration in the atmosphere
Commonly used Unix text editors:
vi,emacs,nano, etc.If in JupyterHub, find the
user_nlfile on the left sidebar, click, edit, and saveNamelist changes are usually done before
./case.buildComplete documentation about the namelist variables can be found on the CESM webpage.
1.8. Summary#
CESM is a software primarily in FORTRAN and You need to build the executable.
Like managing an EV company, you deal with multiple workplaces. What are they?
Build and run a CESM case in four steps. What are they?
How do you further customize the simulation?
1.9. Optional advanced resources#
Check out the full annual CESM Tutorial here
visualCaseGen: a GUI that runs on JupyterLab and guides the users through the process of creating CESM cases, e.g., choosing appropriate compsets and grids.